Introduction
Neo4J is a NoSQL graph database. What that means is that the database stores its data as a set of interconnected nodes. There is no strict defined schema for the database, so you get a lot of flexibility here.
In this tutorial I am going to show you the basics of working with Neo4J. I will be using maven to build the example application.
Setting up the environment
Create an empty Maven project and add to dependencies:
<dependency> |
And this is all you need to try out Neo4J.
Writting some code
For the purpose of this tutorial we will be using embedded database.
EmbeddedGraphDatabase database = new EmbeddedGraphDatabase(PATH); |
The PATH is a path where to store the database. If it’s ‘/tmp/database’ or ‘C:\database’ a folder database will be created and all Neo4J database files will be stored there. Method shutdown tells database to commit any pending changes, close all the file handles and finish operating.
Neo4J is fully ACID compliant which isn’t so common for NoSQL databases. Of course that means we have transaction support, furthermore Neo4J requires you to perform all your operations inside a transaction.
Transaction transaction = database.beginTx(); |
If the transation reaches transaction.success(); the transaction is marked for commit and it will be done when transaction.finish() is called. However, if at the moment of calling transaction.finish() success() hasn’t been called or transaction was explicitly marked for rollback with transaction.failure() it will be rolled back.
Nodes
In Neo4J data is stored in Nodes. Nodes have properties and relationships. Lets create a node student with a name property.
Node student1 = database.createNode(); |
Properties can be any Java object, primitive type (will be auto-boxed) or an array. Notice, you don’t need to explicitly save the entity, any modifications done within a transaction will be committed during transaction.finish().
Relationships
Now the important part in a graph database distinguishing it from others is relationships. Lets create a student attends a course relationship.
First we need to define our relationship typepublic enum StudentRelationship implements RelationshipType {
ATTENDS
}
Relatioship is an enum which extends RelationshipType.
Node algebra = database.createNode(); |
Relationships can also have properties. Lets say student attends algebra at 12 am.
student1AttendsAlgebra.setProperty("at", "12am"); |
So what we have can be illustrated like this
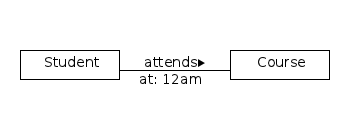
We can delete relationships and nodes by simply calling delete() method.
student1AttendsAlgebra.delete(); |
Querying
If we have data stored we will eventually want to get it out. The most basic type of querying in most databases is querying object by its id. In Neo4J all nodes have ids assigned to them. So you can do something like algebra.getId() to find out the id and of course we can find a node by id:
Node node = database.getNodeById(someId); |
All nodes in Neo4J have unique ids in the database scope (in contrast with relational databases where you can have unique ids in the table scope).
You can also query nodes by their properties. And for this reason Neo4J allows building indexes (a term is familiar to relational database programmers).
Index<Node> studentIndex = database.index().forNodes("students"); |
Neo4J builds indexes by using Lucene.
And we can query the index:
Node student = studentIndex.get("name", "John").getSingle(); // If we need just one John |
The same approach works with indexes for relationships, in this case you use .forRelationship(“indexName”).
The power of querying a graph database lies in it’s graph traversal capabilities. I won’t be covering graph traversal APIs, which can be handy, but more often than not you would be relying on the query language.
Cypher - the query language
Cypher is a query language for Neo4J, which allows traversing the graph and getting results in many ways. For die hard SQL fans, such query language is a change, but personally I find it more intuitive, especially when it comes to navigating relationships, beats joins by far.
To illustrate Cypher, lets update our database model a little. But first you may need to add additional dependency:
<dependency> |
// Relationships |
So what we get here is student attending Algebra and Literature courses of which each have their assigned lecturers. Lets try to query which lecturers does the student John has.
ExecutionEngine engine = new ExecutionEngine(database); |
Now if we’re to iterate through nodes we will get Nodes for lecturers Richard and Hammond. We can also access properties directly by changing return statement to RETURN lecturer.name and getting column as “lecturer.name”.
ExecutionEngine engine = new ExecutionEngine(database); |
Note, that Cypher currently only supports reading data, no statements for creating, updating or removing data exists.
So this ends my introductory Neo4J tutorial. Play with it and decide whether Neo4J is something you would consider for your next project.